
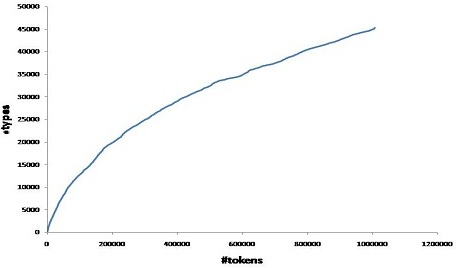
Heap's Law
As we gather larger copora (more instances of tokens), the corresponding number of distinct types gets diminished as we exhaust the discovery of full vocabulary. This phenomenon can be explained by the Heap's law which is formulated as:
V = f(n) = Knβ
where V = types n = tokens K and β are free parameters determined empirically
Objective
The objective of this experiment is to understand the relation between types and tokens with increasing corpus size.